2020. 7. 23. 01:34ㆍubuntu
저번 편에서는 ubuntu20.04 LTS 버전을 내 서버에 설치하는 부분까지 진행했다.
사실 이 시리즈는 친절하게 설치 방법을 알려준다는 목적보다는, 내 스스로의 기록과 회고 측면에 가깝기 때문에 중간중간 많은 부분이 생략될 수 있다.
이점 양해 부탁드린다.
처음으로 접해본 리눅스는 ubuntu18.04 였는데, 당시에 APM을 수동 설치(컴파일 설치) 하면서 개고생 했던 기억이 생생하다.
자동 설치의 존재를 몰랐던 건 아니지만, 아무튼 리눅스를 처음 접하던 당시에 APM 설치는 고난과 역경의 연속으로 기억에 남는다.
설치 단계의 여러 옵션들을 익히느라 어려웠던 점도 있지만, 설치 경로가 기본이 아니다 보니 나중에 호환성과 conf 수정 등에서 정말 많은 난관을 겪었다.
하지만 지금은 그럴 필요가 굳이 없으니 자동설치로 가뿐히 APM을 설치한다.
APM은 Apache, PHP, MySQL or MariaDB를 말한다.
APM 설치에 관한 글은 구글링을 해보면 수십가지가 넘게 있다. 여기엔 그중 하나를 첨부한다.
Ubuntu 18.04에 LAMP ( Apache2, MySQL , PHP 7) 설치하는 방법
Apache2 웹서버, MySQL 데이터베이스 서버, PHP를 Ubuntu에 설치하는 과정을 소개합니다. LAMP는 운영 체제와 오픈 소스 소프트웨어 스택의 조합으로 Linux, Apache, MySQL, PHP의 첫글자만 가지고 만든 약어��
webnautes.tistory.com
무사히 설치를 마친 후, 내 목표 중 하나인 React, Django 프로젝트의 뼈대를 만들었다.
/home/django/ 디렉토리 아래에 각각 frontend , backend 폴더를 만들었으며,
frontend폴더엔 react-create-app 으로 기본적인 app을, backend폴더엔 Django 프로젝트를 Django-Rest-Framework와 함께 형태만 만들어 놓았다.
React랑 Django는 처음 접하다보니, 초심자의 마음으로 여기저기 기웃거리면서 구축했다.
간단한 react JS + Django 어플리케이션 만들기
간단한 react JS + Django 어플리케이션 만들기 일단 프로젝트를 시작하기 전에 서론이 길다. react와 django가 동작하는 방식에 대해선 관심 없고 단지 어떻게 만드는 지에 대해서만 관심있는 사람이라
this-programmer.com
정말 잘 쓰인 글이다. 감사히 참고해서 무사히 구축했다.
위 포스팅에서 예제로 나온 post 앱 외에, 내가 기존에 aws에 구축했던 뉴스 크롤링 서비스도 Django App으로 넣고 싶었다.
초보자의 입장에서 하면서 배우는 것 만큼 빨리 느는 게 없다고 생각하기 때문에, 바로 진행했다.
> python manage.py startapp newsroom
> python manage.py migrate
먼저 백엔드 폴더에서 newsroom 앱을 만들고, 메인 프로젝트의 setting.py에서 newsroom앱을 추가한다.

그다음 모델을 정의한다. 뉴스 데이터 같은 경우에는 json으로 dump 해서 저장하는데, django 모델에서 JsonField를 사용하려면 MySQL이랑 연동을 해야 한다. (Django 기본 DB는 sqlite3이다)
놀랍게도! 귀찮은 나머지 일단 TextField에 저장했다.
나중에 MySQL이랑 연동하고 전반적인 리팩토링을 할 예정이다.
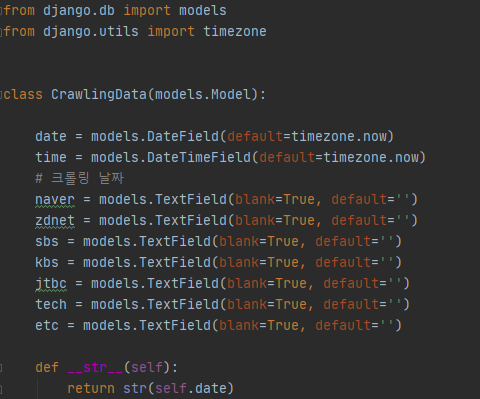
날짜별로 크롤링을 하기 때문에 date, 크롤링 한 시간은 뭔가 나중에 필요할 것 같아서 datetime을 넣었다.
나머지 필드는 뉴스를 가져오는 필드별로 대충 텍스트 필드... 나중에 다시 보면 분명 부끄러울 것이다.
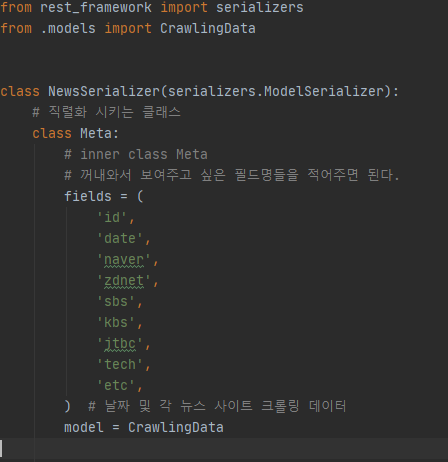
view에서 데이터를 보여주는 규칙을 정할 때, serializer가 필요하다.
Django rest-framework Serializer
Serializer
medium.com
serializer는 queryset과 model instance 같은 것들을 쉽게 Json , Xml 또는 기타 데이터 형태로 렌더링 할 수 있게 해 준다....라고 한다.
쉽게 생각해서 view에서 보여줄 방식을 정의하는 객체라고 보면 될 것 같다. serializer 여러개를 선언해서 각 뷰 클래스마다 다른 serializer를 사용 할 수도 있을 것이다.

보여줄 방식을 정했으니 보여줄 녀석들만 정하면 되겠다.
ListNews 에서는 크롤링 된 모든 날짜의 뉴스를 보여준다.
DetailNews 에서는 한 날짜의 뉴스를 보여준다.
TodayNews 에서는 오늘 날짜의 뉴스만 보여준다.
TodayNews 쿼리셋을 filter를 통해서 했는데, 저 방식은 12시가 넘어가는 순간 데이터 조회가 불가능하다.
date는 지났는데 크롤링은 매일 아침 9시에 되기 때문에...
이 부분은 쿼리셋 공부를 해서 추후 수정하기로 한다. (아직 오늘 데이터가 없으면 id값이 제일 큰 데이터를 보여주는 방식으로 변경 예정)
자, 이제 보여줄 방식, 보여줄 녀석들을 다 정했다.
근데 어떤 경우에 모두 보여주고 어떤 경우에 오늘 뉴스를 보여줄 것인지는 아직 정하지 않았다.
이 부분을 정하는 곳이 바로 urls.py이다.

들어오는 rul의 패턴을 분석해서, 패턴별로 어떤 view를 매칭시킬지 정한다.
주석으로 적어놓은 것을 보면 되겠다.
url pattern에 대한 부분은 이곳을 참고하면 된다. 나도 더 공부해야 한다. 대충 정규표현식 비슷하다고 보면 되겠다.
URL dispatcher | Django 문서 | Django
The Django Software Foundation deeply values the diversity of our developers, users, and community. We are distraught by the suffering, oppression, and systemic racism the Black community faces every day. We can no longer remain silent. In silence, we are
docs.djangoproject.com
이제 크롤링한 뉴스를 담을 틀도 만들었고!
api를 통해 값을 보내줄 준비도 마쳤고!
데이터(알맹이)만 있으면 된다.
알맹이를 가져와서 Django에 저장하는 부분은 이 포스팅을 참고했는데, 나는 기존에 selenium으로 만들어 둔 크롤링 파일이 있어서 포스팅처럼 BS를 사용하진 않았다.
나만의 웹 크롤러 만들기(4): Django로 크롤링한 데이터 저장하기 - Beomi's Tech blog
좀 더 보기 편한 깃북 버전의 나만의 웹 크롤러 만들기가 나왔습니다! (@2017.03.18) 본 블로그 테마가 업데이트되면서 구 블로그의 URL은 https://beomi.github.io/beomi.github.io_old/로 변경되었습니다. 예제 �
beomi.github.io

지저분한 코드라서 내놓기 부끄럽다.
장고의 설정값들을 가져오고, 모델에서 선언한 크롤링 데이터 모델 클래스를 가져온다.
from newsroom.models import CrawlingData
참고로 코드들을 캡쳐해서 첨부하는 건 누가 가져가지 않았으면 하는 괘씸한 마음이 아니라, 네이버 캡쳐가 너무 편해서 그런 것이다...
장고 + 리액트 코드는 깃헙에 공개중이다. 이 포스팅을 하는 시점은 첫 Commit 시점이니 참고하시길...
Jonghakseo/unqocn_project
개인 프로젝트 저장 공간입니다. Contribute to Jonghakseo/unqocn_project development by creating an account on GitHub.
github.com

이어서 아직 crawler.py 파일이다.
크롤링 한 데이터를 위에서 가져온 크롤링 데이터 모델 객체에 잘 저장한다.
참고로 date와 time 필드는 입력하지 않았기 때문에 기본값인 now로 잘 저장된다.
이제 crawler.py를 실행해보자. (미리 설정한 가상환경에서 실행한다)


콘솔창 색이 이상한 이유는 zsh를 사용하고 있기 때문이다.

이제 값이 잘 저장되었으리라 기대하고 api로 넘어가서 값을 조회해보자
참고로 api 부분은 설명이 부실했는데, 위에 첨부한 포스팅에서 워낙 잘 나와있기 때문이다.

...사실 깜빡했는데, api로 넘어갈 것 없이, django admin에서도 확인이 가능하다

부족한 부분이 많지만 일단 이렇게 크롤링 데이터를 받아오는 것에 성공했다.
하지만 진정한 위기는 예상치 못한 곳에서 찾아오는 법....
crontab에서 크롤링 자동화가 계속 실패하는 현상이 일어났다.
파폭 webdriver를 제대로 인식하지 못하는 문제였다.
알고보니 crontab에서 가상환경의 python을 실행할 때 환경변수까지 가져오진 않는다는 부분이 문제였다.
크롤러.py 상단에
sys.path.append("/home/django/backend")로 기본 경로를 추가한 부분,
크롤링 함수 내에서
options = Options()
options.headless = True
driver = webdriver.Firefox(executable_path=r"/home/django/unqocn_venv/bin/geckodriver", options=options)
웹 드라이버 옵션을 headless로, geckodriver 경로를 명시해주는 부분,
마지막으로 crontab -e

DISPLAY=:0 을 추가하는 것으로 몇 시간의 에러 두더지 잡기 게임이 끝이 났다.
이런저런 삽질을 많이 했고, 현재는 매일 아침 9시에 크롤링이 문제 없이 되는 상황이다.

뉴스 크롤링 같은 경우에는 추후에 React와 연계하여 지난 IT 뉴스를 모아 볼 수 있는 서비스를 만들 예정이다.
React, Django 초기 세팅에 대한 글은 이 정도로 마무리하도록 하겠다.