Python으로 단톡방 채팅 내용 키워드 분석하기
2020. 6. 28. 17:09ㆍ취미로 하는 개발
일정이 붕 떠서 심심하던 차에, 문득 친구들이랑 떠드는 단톡방이나 한 번 까보고 싶어졌다.
하려는 일의 순서는 다음과 같다.
- 단톡방 대화내용 확보
- 대화내용을 화자별로 구분하여 저장
- 각 문장에서 단어를 추출하여 사용 빈도가 높은 순서대로 정렬

일단 대화 내보내기를 통해 단톡방의 내용을 txt파일로 받아놓는다.
데이터가 어떻게 구성되어 있는지를 확인해야 원하는 부분을 추출할 수 있기 때문에 txt파일을 열어서 확인해본다.
데이터 맨 윗줄은 단톡방 이름, 인원, 저장된 날짜가 노출되어 있었다.
마지막 채팅 이후 새 채팅이 시작된 시점에 날짜가 지난 경우 {시간}만 노출된 데이터도 있었고,
쭉 흝어보니 대화 데이터는 {시간},{이름} : {내용} 으로 표현되어 있었다.
내가 필요로 하는 데이터는 오직 {이름},{내용} 뿐이므로 해당 내용을 추출하는 과정이 필요했다.
먼저 친구들 각각의 채팅 내용을 따로 저장하는 과정을 거쳤다.
DataExtractor.py
chat = open("C:/Users/rejec/Documents/NLP/KakaoTalkChats.txt", encoding="utf-8")
#추출을 위한 채팅 원본 파일로, 읽기 모드로 가져온다. 'r'값은 기본값이라 생략했다.
mhchat = open("C:/Users/rejec/Documents/NLP/MhChats.txt", 'w', encoding="utf-8")
sikchat = open("C:/Users/rejec/Documents/NLP/SikChats.txt", 'w', encoding="utf-8")
inschat = open("C:/Users/rejec/Documents/NLP/InsChats.txt", 'w', encoding="utf-8")
zingchat = open("C:/Users/rejec/Documents/NLP/ZingChats.txt", 'w', encoding="utf-8")
mechat = open("C:/Users/rejec/Documents/NLP/MeChats.txt", 'w', encoding="utf-8")
#각 사용자별로 새 텍스트 파일을 생성해준다. 'w' 쓰기모드
mh = "명룡 : "
sik = "정시기 : "
ins = "박상용 : "
zing = "징도 : "
me = "회원님 : "
# 친구들 이름 +" : "
# 해당 문자열이 들어있으면 추출해서 따로 저장할 예정
nonchating = ['사진','샵검색','이모티콘','동영상']
# 일반적인 채팅 내용이 아닌 것들은 예외처리를 해주기 위해 리스트에 넣는다
while True:
line = chat.readline()
#채팅 내용에서 한 줄씩 가져와준다
#print(line)
if not line:
break
#더 가져올 줄이 없으면 break
isOk = True
#예외처리에 필요한 변수 하나 선언
for item in nonchating:
#아이템 안에 들어있는 요소들마다
if item in line:
#줄에 그 내용이 있으면
isOk = False
#다음 단계로 넘기지 마
break
if isOk:
#문제가 없으면 Keep Going~
if mh in line:
#mh라는 친구가 한 말이면
line = line.split(" : ")[1]
#split으로 대화 내용만 추출한다.
mhchat.write(line)
#mhchat파일에 추출한 대화 내용을 써준다.
elif sik in line:
line = line.split(" : ")[1]
sikchat.write(line)
elif ins in line:
line = line.split(" : ")[1]
inschat.write(line)
elif zing in line:
line = line.split(" : ")[1]
zingchat.write(line)
elif me in line:
line = line.split(" : ")[1]
mechat.write(line)
#python에는 스위치문이 없어서 elif나 아니면 딕셔너리를 사용한다고 한다.
chat.close()
mhchat.close()
sikchat.close()
inschat.close()
zingchat.close()
mechat.close()
#file 객체 다 닫아줌
이렇게 하면 원하는 대로 대화내용만 쏙쏙 빼서 txt파일로 생성이 되는 부분을 확인 할 수 있다.

실제로 파일을 열어보면 대화 내용만 착하게 저장되어 있다.
이제 단어의 빈도수만 파악하면 되겠다.
띄어쓰기가 되지 않은 문장도 자연어 처리를 통해 단어로 분석할 수 있지만
그렇게까지 하긴 싫어서 그냥 공백으로 구분하였다.
import operator
mhchat = open("C:/Users/rejec/Documents/NLP/MhChats.txt", 'r', encoding="utf-8")
mhchatfreq = open("C:/Users/rejec/Documents/NLP/MhChatsFreq.txt", 'w', encoding="utf-8")
sikchat = open("C:/Users/rejec/Documents/NLP/SikChats.txt", 'r', encoding="utf-8")
sikchatfreq = open("C:/Users/rejec/Documents/NLP/SikChatsFreq.txt", 'w', encoding="utf-8")
inschat = open("C:/Users/rejec/Documents/NLP/InsChats.txt", 'r', encoding="utf-8")
inschatfreq = open("C:/Users/rejec/Documents/NLP/InsChatsFreq.txt", 'w', encoding="utf-8")
zingchat = open("C:/Users/rejec/Documents/NLP/ZingChats.txt", 'r', encoding="utf-8")
zingchatfreq = open("C:/Users/rejec/Documents/NLP/ZingChatsFreq.txt", 'w', encoding="utf-8")
mechat = open("C:/Users/rejec/Documents/NLP/MeChats.txt", 'r', encoding="utf-8")
mechatfreq = open("C:/Users/rejec/Documents/NLP/MeChatsFreq.txt", 'w', encoding="utf-8")
#기존에 저장한 각 화자별 대화 내용을 가져오고,
#단어와 빈도수를 저장할 freq파일을 생성한다.
#function을 하나 만들어서 간단히 처리해보자
def get_freq(chat_file, out_file):
#chat_file은 대화 내용이 담긴 텍스트 파일, out_file은 빈도를 저장할 file이다.
# 생각해보니 그냥 chat_flie만 받아서 해도 되었을텐데... 또 바보같이 했다.
freq = {}
# 단어와 빈도를 저장할 딕셔너리 생성
while True:
line = chat_file.readline()
if not line:
break
#읽어오는 부분은 동일하다
lines = line.split(" ")
#공백으로 단어를 구분한다
for i in lines:
#구분한 단어들을,
i = i.replace('\n', '')
#개행문자를 제거한 후
count = freq.get(i, 0)
#기존에 저장된 빈도 딕셔너리에서 가져온다
#없는 값이라면(처음 보는 값이라면) 0과 함께 저장
freq[i] = count + 1
#이렇게 하면 i라는 단어의 value는 기존에 존재했다면 +1, 처음이라면 1이 저장된다
frequency_list = sorted(freq.items(), key=operator.itemgetter(1), reverse=True)
#저장된 딕셔너리의 값을 빈도수가 높은 순서대로 재정렬 해준다. 낮은 순서대로 하려면 reverse=False
'''
# sorted(dict.items(), key=operator.itemgetter(0))
# key=operator.itemgetter(0)는 정렬하고자 하는 키 값을 0번째 인덱스로 한다.
# 딕셔너리 자료형에서 0번째 인덱스는 Key.
# 1번째 인자는 Value니까 1로 해야한다.
'''
for words in frequency_list:
out_file.write(words[0] + " : " + str(words[1]) + "\n")
#정렬된 딕셔너리 자료형을 보기 좋게 {단어} : {빈도} \n 로 저장한다.
chat_file.close()
out_file.close()
get_freq(mhchat, mhchatfreq)
get_freq(sikchat, sikchatfreq)
get_freq(inschat, inschatfreq)
get_freq(zingchat, zingchatfreq)
get_freq(mechat, mechatfreq)
#5명 반복
실행 후 결과를 까보도록 하자.
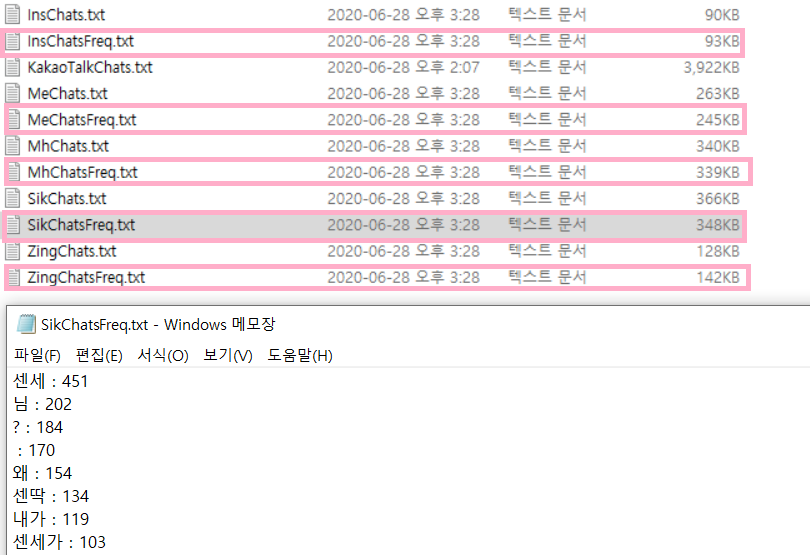
빈도가 높은 단어 순서대로 {단어} : {빈도수} 확인이 가능하다.
저 공백 부분은 예외처리를 해줘야겠다.
아무튼 끝~